实验 1 —— C 语言词法分析程序的设计与实现
1 实验 1 —— C 语言词法分析程序的设计与实现
1.1 实验内容及要求
1.1.1 实验内容要求
- 可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
- 可以识别并跳过源程序中的注释。
- 可以统计源程序中的语句行数、各类单词的个数、以及字符总数,并输出统计结果。
- 检查源程序中存在的词法错误,并报告错误所在的位置。
- 对源程序中出现的错误进行适当的恢复,使词法分析可以继续进行,对源程序进行一次扫描,即可检查并报告源程序中存在的所有词法错误。
1.1.2 实验方法要求
方法1:采用C/C++作为实现语言,手工编写词法分析程序。(必做)
方法2:编写LEX源程序,利用LEX编译程序自动生成词法分析程序。
1.2 程序设计说明
1.2.1 本C语言词法分析器的词法说明
- 标识符:
- 必须以
字母a~z、 A~Z或下划线开头,后面可跟任意个(可为0)字符,这些字符可以是字母、下划线和数字,其他字符不允许出现在标识符中。 - c99规定标识符长度在
63个字符以内,但根据不同的编译器、操作系统,限制也不同,在此不限制标识符长度。
- 必须以
- 保留字:
- 32个保留字
- 类型说明保留字(14):
int long short float double char unsigned signed const void volatile enum struct union - 语句定义保留字(13):
if else goto switch case do while for continue break return default typedef - 存储类说明保留字(4):
auto register extern static - 长度运算符保留字(1):
sizeof
- 常量:
- 整数常量
- 前缀:
0x 或 0X表示十六进制,0表示八进制,不带前缀则默认表示十进制 - 后缀:
u 或 U表示无符号整数(unsigned),l 或 L表示长整数(long)。二者的顺序任意。
- 前缀:
- 浮点常量
- 可以有小数形式和指数形式。指数使用
e 或 E引入 - 后缀:
f 或 F表示 float,l 或 L表示 long double - 前缀:浮点常量没有前缀,使用 0x 或 0 做前缀表示基数是不合法的。
- 可以有小数形式和指数形式。指数使用
- 整数常量
- 符号:
- 运算符:
- 算术运算符:
+ - * / % ++ -- - 关系运算符:
== != > < >= <= - 逻辑运算符:
&& || ! - 位运算符:
& | ^ ~ << >> - 赋值运算符:
= += -= *= /= %= <<= >>= &= ^= |= - 其他运算符:
sizeof , () [] & * ?: -> .
- 算术运算符:
- 其他符号:
- 分隔符:
; : {} - 预处理符号:
# - 换行连接符:
\ - 字符和字符串:
'' ""
- 分隔符:
- 运算符:
- 注释标记:
- 单行注释:
// 单行注释 - 块注释:
/* ... */
- 单行注释:
- 空白:
空格符、换行符、制表符
1.2.2 设计词法分析程序的状态转换图
1.2.2.1 标识符——根据标识符定义可以得到状态转换图如下:

1.2.2.2 符号——按照起始符号将所有符号进行归类整理如下:
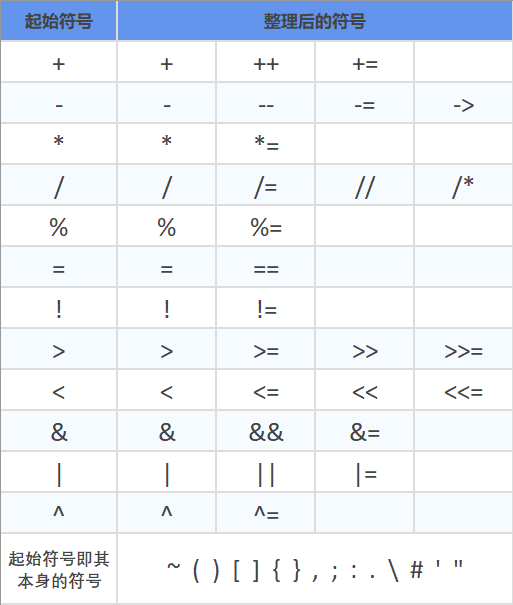
注意 .这一符号,既有可能是用于结构体,也可能出现在常量的小数中,需要特殊处理(详见第3条常量的状态转换图)
1.2.2.3 常量——设计状态转换图,见(4)
1.2.2.4 综合上述元素,得到完整状态转换图如下:
其中,hdigit 表示 16进制的数字(0-f),0digit 表示 8进制的数字(0-7)。绿色笔标注为后期调试中添加的漏掉的分支。

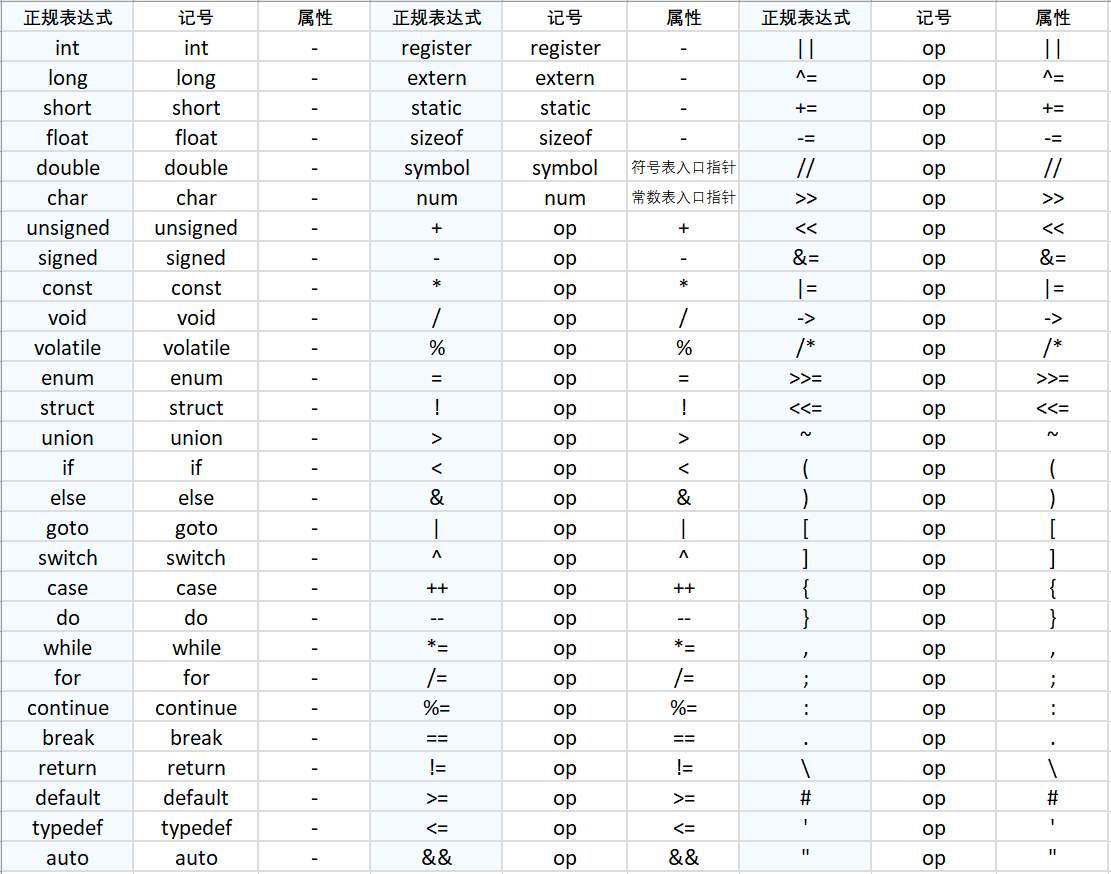
1.2.3 翻译表
1.2.4 输出形式
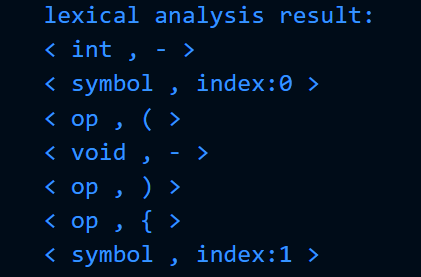
1.2.4.1 记号输出
利用翻译表,将识别出的单词的记号以二元式的形式输出:<记号,属性>,如下例:
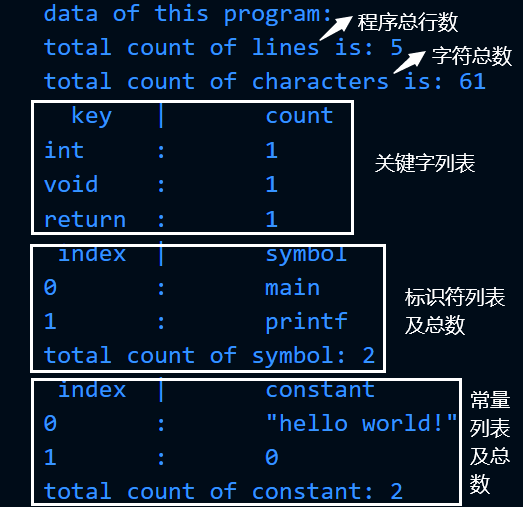
1.2.4.2 统计结果输出
在词法分析完成后,将词法分析的结果加以统计输出,包括程序行数、程序字符总数、用到的关键字及对应出现次数、用户自定义标识符总数和列表、常量总数和列表,如下例:
1.2.4.3 词法错误输出
在输出二元组的过程中,如果检测到词法错误,将会以如下形式输出:


1.3 源程序
Compiler_Labs/Lab1_lexical_analysis at master · thatmee/Compiler_Labs (github.com)
1.4 程序测试及成果说明
1.4.1 测试程序1,简单测试:
1 | int main(void) |
输出如下图:
可见,本词法分析器能够正确识别标识符、简单的符号和常量。
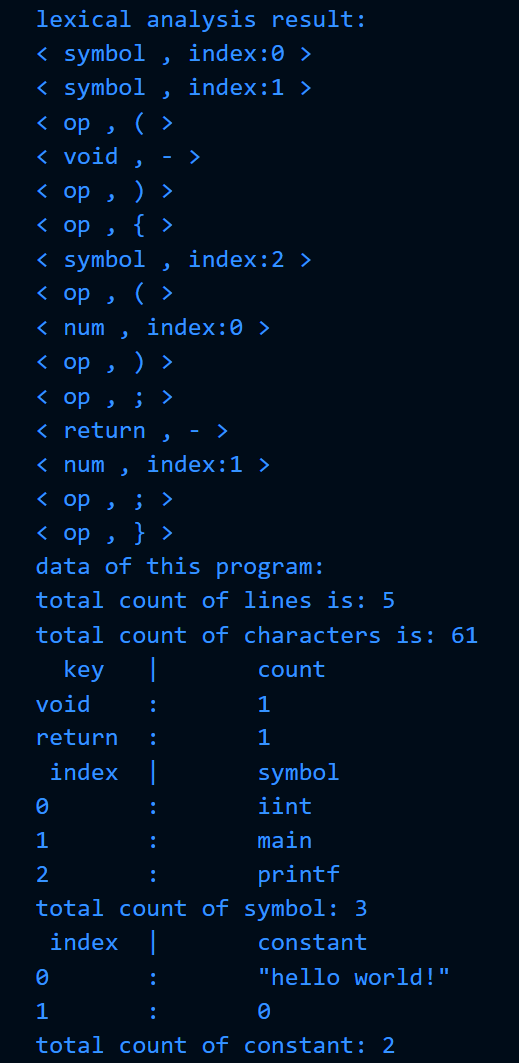
1.4.2 测试程序2,各种特殊常量、字符的测试:
1 |
|
输出如下图(仅截取重要片段):
可见,词法分析器识别出错误:0x.。对应的源代码为:0x.36;根据前文的词法说明,0x后是不可能出现小数点的,因此报错。同时,根据图2中index为4的常量36可知,词法分析器将0x.之后的36识别成了一个常量,可见错误恢复功能正常。

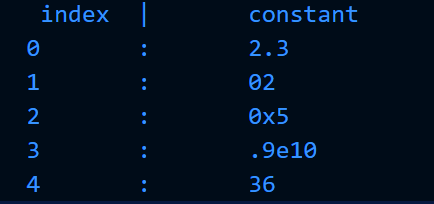
另外,行数和字符数统计功能也正常:

1.4.3 测试程序3,块注释、词法错误报告测试:
1 |
|
输出如下图(仅截取重要片段):
可见词法分析器检测出了标识符的错误:出现了不合法的字符@,同时正常识别到了块注释。
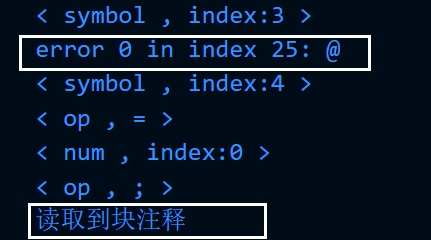
1.4.4 测试程序4,双缓冲区、运算符、常量测试:
1 |
|
输出如下图(仅截取重要片段):
可见关键字统计正常,大量运算符和常量识别正常:
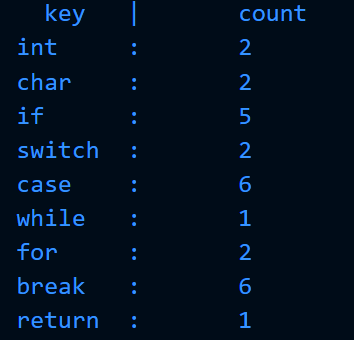
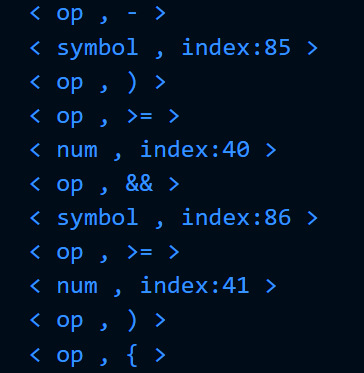
另外,为了测试双缓冲区的正确性,在运行这一程序时我将缓冲区大小 BUFFER_SIZE 改为500,使其能够进行多次缓冲区的替换。可见缓冲区功能也正常。
1.5 值得注意的问题总结
- C语言中各种特殊符号及常量,不清楚它们属于词法分析还是语法分析的范畴
使用IDE进行测试,输入不同形式的常量及符号,查看IDE是否报错,明确词法分析需要进行检测的内容。
- 预处理指令
所谓预处理是指在进行编译的第一遍扫描(词法分析和语法分析)之前所做的工作,预处理是C语言的一个重要功能,它由预处理程序负责完成。当对一个源文件进行编译时,系统将自动引用预处理程序对源程序中的预处理部分作处理,处理完毕自动进行对源程序的编译。
- 常量的类型繁多,有前缀有后缀,还有.开头的小数,不知道如何检测
一步步进行分析,绘制出了状态转换图。同时在编程过程中,不断调试修改,解决了这一问题。
- 同一符号多次判断以及漏字符的问题,getChar()函数以及retract()函数需要使用的地方
起初选择了在需要回退的地方使用retract()函数,但在调试中发现一些漏洞,应该是那时候状态转换图还不太完善,对各种状态的转移(尤其对出口的处理)不清楚,我删除了所有retract()函数,只使用getChar()对向前指针进行控制,解决了bug。同时,在后续调试程序和完善状态转换图的过程中,我逐渐理清了getChar()函数以及retract()函数需要使用的地方,如果按照一开始的选择使用retract()函数,应该在每次出口的时候统一执行getChar()。