程序设计实践小作业 3 —— 性能
1 程序设计实践小作业 3 ——性能
1.1 题目及要求
1.1.1 题目
wordst_bad.cpp用于统计一文本文件里的每个单词的数量以及出现在文本文件中的行号,最后按照出现次数从大到小排列显示出来,如果出现的行号比较多,那么只显示前20次出现的行号。
1.1.2 要求
- 测试当前给出的wordst_bad.cpp,给出这些数据:
- 测试用的文本的单词数量
- 文本所含的不同单词的数量(根据运行结果得出)
- 排名前三的单词及其数量
- 执行所用时间(time命令的显示结果)
- 尝试找出程序中的性能问题,并加以改进,给出:
- 改进之后的源程序wordst_good.cpp
- 修改的依据
- 与wordst_bad相同测试数据下的执行时间比较(time命令的显示结果)
- 计算性能提高的比例
1.2 测试及结果分析
测试用例:请见附件
test.txt测试用的文本的单词数量:58676(通过输出结果以及 Excel 软件得出)
文本所含的不同单词的数量:请见附件
result.txt排名前三的单词及其数量:
1
2
3
4WORD COUNT
the 2704
and 2150
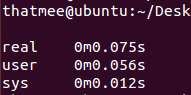
to 1486执行所用时间:
1.3 性能优化
1.3.1 使用 gprof 命令确定瓶颈
1 | g++ -pg -o wordst_bad wordst_bad.cpp |
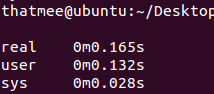
如下图,可知在 main 函数中,主要花费时间的函数是
statisWord
于是观察
statisWord的调用关系,如下图所示,可以发现在statisWord中,主要花费时间的是find函数和[]操作符
1.3.2 优化
1.3.2.1 优化数据结构
经过查询资料,了解到 hash_map 是比 map 更为高效的数据结构,在 C++11 中,规定了使用
unordered_map来代替 hash_map,因此我将 map 数据结构更换为unordered_map:1
2
typedef std::unordered_map<std::string, WordInfo*> WordsStatis;
注意这时应使用 C++11 进行编译,添加
-std=c++11编译选项:1
g++ -std=c++11 -pg -o wordst_good wordst_good.cpp
1.3.2.2 优化 statisWord 函数中对 find 和 [] 操作符的调用
根据之前确定的瓶颈,我尝试修改
find和[]的调用次数,尽量保存一些变量,从而减少遍历map的次数。如下所示,我将第一次调用find的结果保存起来,之后直接在这个迭代器的基础上进行增删改,取消了对[]的两次调用,提升了效率:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void statisWord(WordsStatis& wordsStatis, std::string& word, int lineNo)
{
WordsStatis::iterator a = wordsStatis.find(word);
if(a == wordsStatis.end())
{
// 如果当前统计表中没找到,则新增一项
WordInfo* wordInfo = new WordInfo;
wordInfo->lines.push_back(lineNo);
wordsStatis.insert(a, WordPair(word, wordInfo));
}
else
{
// 如果找到了,则增加一个新的行号
a->second->lines.push_back(lineNo);
}
}
1.3.3 优化结果
原执行时间
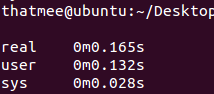
优化数据结构后执行时间
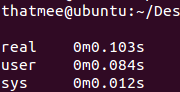
优化 find 和 [] 调用后的执行时间